
 服务热线:
服务热线: 高精度低成本游戏3D人脸重建方案腾讯AI Lab ICCV 2023论文解读
发布日期: 2024-03-18 03:02:43 作者: bob线上官网原标题:高精度低成本游戏3D人脸重建方案,腾讯AI Lab ICCV 2023论文解读
3D 人脸重建是一项大范围的应用于游戏影视制作、数字人、AR/VR、人脸识别和编辑等领域的关键技术,其目标是从单张或多张图像中获取高质量的 3D 人脸模型。借助摄影棚中的复杂拍摄系统,当前业界成熟方案已可得到媲美真人的毛孔级精度的重建效果 [2],但其制作成本高、周期长,一般仅用于 S 级影视或游戏项目。
近年,基于低成本人脸重建技术的交互玩法(如游戏角色捏脸玩法、AR/VR 虚拟形象生成等)受到市场欢迎。用户只需输入日常可获取的图片,如手机拍摄的单张或多张图片,就可以快速得到 3D 模型。但现有方法成像质量不可控,重建结果精度较低,无法表达人脸细节 [3-4]。如何在低成本条件下得到高保线D 人脸,仍是一个未解的难题。
人脸重建的第一步是定义人脸表达方式,但现有主流的人脸参数化模型表达能力有限,即使有更多约束信息,如多视角图片,重建精度也难以提升。因此,腾讯 AI Lab 提出了一种改进的自适应骨骼 - 蒙皮模型(Adaptive Skinning Model,以下简称 ASM)作为参数化人脸模型使用,利用人脸先验,以高斯混合模型来表达人脸蒙皮权重,极大降低参数量使其可自动求解。
测试表明,ASM 方法在不需要训练的前提下仅使用少量的参数,即明显提升了人脸的表达能力及多视角人脸重建精度,创新了 SOTA 水平。相关论文已被 ICCV-2023 接收,以下为论文详细解读。

从 2D 图像得到信息量更大的 3D 模型,属于欠定问题存在无穷多解。为了使其可解,研究者将人脸先验引入重建,降低求解难度的同时能以更少的参数来表达人脸 3D 形状,即参数化人脸模型。当前大部分参数化人脸模型都是基于 3D Morphable Model (3DMM) 及其改进版,3DMM 是 Blanz 和 Vetter 在 1999 年首次提出的参数化人脸模型 [5]。文章假设一张人脸能够最终靠多个不同的人脸线性或非线性组合得到,通过收集数百个线D 模型构建人脸基底库,进而组合参数化人脸来表达新的人脸模型。后续研究通过收集更多样的线],以及改进降维方法来优化 3DMM [8, 9]。
然而,3DMM 类人脸模型的鲁棒性高但表达能力不够。尽管他能够在输入图像模糊或有遮挡的情况下稳定地生成精度一般的人脸模型,但当使用多张高质量图像作为输入时,3DMM 表达能力有限,不能利用上更多的输入信息,因此限制了重建精度。这种限制源于两方面,一是方法本身的局限性,二是该方法依赖于人脸模型数据的收集,不仅数据获取成本高,且因人脸数据的敏感性,在实际应用中也难以广泛复用。
为了解决现有 3DMM 人脸模型表达能力不够的问题,本文引入了游戏业界常用的 “骨骼 - 蒙皮模型” 作为基准人脸表达方式。骨骼 - 蒙皮模型是游戏与动画制作的步骤中表达游戏人物角色脸型与表情的一种常见的人脸建模方式。它通过虚拟的骨骼点与人脸上的 Mesh 顶点相连,由蒙皮权重决定骨骼对 Mesh 顶点的影响权重,使用时只需要控制骨骼的运动即可间接控制 Mesh 顶点的运动。
通常情况下,骨骼 - 蒙皮模型需要动画师进行精确的骨骼放置与蒙皮权重绘制,具有高制作门槛与长制作周期的特点。但是现实的人脸中不同的人骨骼与肌肉的形状具有较大的差别,一套固定的骨骼 - 蒙皮系统难以表达现实中多种多样的脸型,为此,本文在现有的骨骼 - 蒙皮基础上进行进一步设计,提出了自适应骨骼 - 蒙皮模型 ASM,基于高斯混合蒙皮权重(GMM Skinning Weights)与动态骨骼绑定系统(Dynamic Bone Binding)进一步提升了骨骼 - 蒙皮的表达能力与灵活度,为每一个目标人脸自适应生成独有的骨骼 - 蒙皮模型,以表达更丰富的人脸细节。
为了提高骨骼 - 蒙皮模型对于建模不同人脸时的表达能力,ASM 对骨骼 - 蒙皮模型的建模方式来进行了全新的设计。
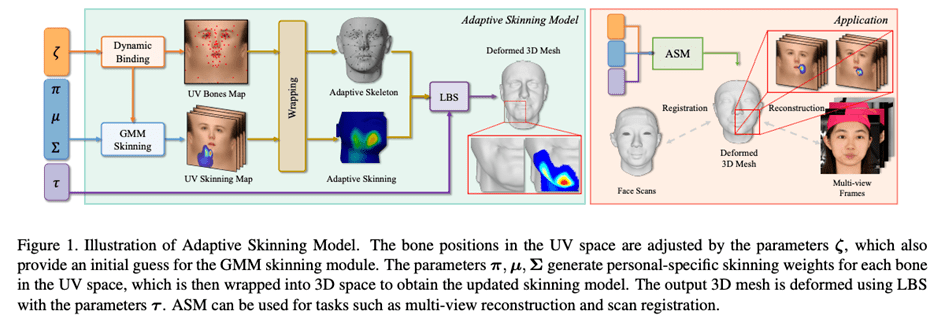
骨骼 - 蒙皮系统通常基于线性混合蒙皮(Linear Blend Skinning, LBS)算法,经过控制骨骼的运动(旋转、平移、缩放)来控制 Mesh 顶点的变形。传统的骨骼 - 蒙皮包含两个部分,即蒙皮权重矩阵与骨骼绑定,ASM 对这两部分分别进行了参数化,以实现自适应的骨骼 - 蒙皮模型。接下来会分别介绍蒙皮权重矩阵与骨骼绑定的参数化建模方法。
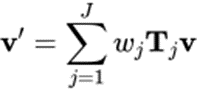
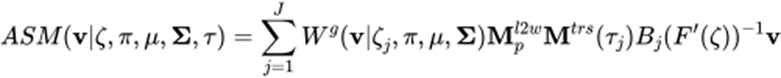
蒙皮权重矩阵是一个 mxn 维的矩阵,其中 m 为骨骼数量,n 为 Mesh 上的顶点数量,该矩阵用于存放每一根骨骼对每一个 Mesh 顶点的影响系数。一般来说蒙皮权重矩阵是高度稀疏的,例如在 Unity 中,每个 Mesh 顶点只会被最多 4 根骨骼影响,除了这 4 根骨骼外,其余骨骼对该顶点的影响系数为 0。传统的骨骼 - 蒙皮模型中蒙皮权重由动画师绘制得到,并且蒙皮权重一旦得到,在使用时将不再发生改变。近年来有工作 [1] 尝试结合大量数据与神经网络学习怎么样自动生成蒙皮权重,但这样的方案有两个问题,一是训练神经网络需要较大量的数据,如果是 3D 人脸或者蒙皮权重的数据则更难获得;二是使用神经网络建模蒙皮权重存在较为严重的参数冗余。是不是真的存在一种蒙皮权重的建模方式,在不需要训练的前提下使用少量的参数即可完整表达整张人脸的蒙皮权重呢?
通过观察常见的蒙皮权重可发现以下性质:1. 蒙皮权重局部光滑;2. 离当前骨骼位置越远的 Mesh 顶点,对应的蒙皮系数通常也越小;而这样的性质与高斯混合模型(GMM)非常吻合。于是本文提出了高斯混合蒙皮权重(GMM Skinning Weights)将蒙皮权重矩阵建模为基于顶点与骨骼某个距离函数的高斯混合函数,这样就能使用一组 GMM 系数表达特定骨骼的蒙皮权重分布。为了进一步压缩蒙皮权重的参数量,我们将整个人脸 Mesh 从三维空间转移到 UV 空间,从而只需要用二维 GMM 并且使用顶点到骨骼的 UV 距离就能计算出当前骨骼对特定顶点的蒙皮权重系数。
对蒙皮权重进行参数化建模不仅使我们能用少量参数表达蒙皮权重矩阵,还使我们在运行时(Run-Time)调整骨骼绑定位置成为了可能,由此,本文提出了动态骨骼绑定(Dynamic Bone Binding)的方法。与蒙皮权重相同,本文将骨骼的绑定位置建模为 UV 空间上的一个坐标点,还可以在 UV 空间中任意移动。对于人脸 Mesh 的顶点,可以通过很简单地通过预定义好的 UV 映射关系将顶点映射为 UV 空间上的一个固定坐标。但是骨骼并没有预先定义在 UV 空间中,为此我们应该将绑定的骨骼从三维空间转移到 UV 空间上。本文中这个步骤通过对骨骼与周围顶点进行坐标插值实现,我们将计算得到的插值系数应用在顶点的 UV 坐标上,就能获得骨骼的 UV 坐标。反过来也一样,当需要将骨骼坐标从 UV 空间转移到三维空间时,我们同样计算当前骨骼的 UV 坐标与临近顶点的 UV 坐标的插值系数,并将该插值系数应用到三维空间中同样的顶点三维坐标上,即可插值出对应骨骼的三维空间坐标。
通过这种建模方式,我们将骨骼的绑定位置与蒙皮权重系数都统一为了 UV 空间中的一组系数。当使用 ASM 时,我们将人脸 Mesh 顶点的形变转变为求解 UV 空间中骨骼绑定位置的偏移系数、UV 空间中的高斯混合蒙皮系数与骨骼运动系数三者的组合,极大地提高了骨骼 - 蒙皮模型的表达能力,实现更丰富的人脸细节的生成。
我们使用了 Florence MICC 的数据集测试了 ASM 在多视角人脸重建任务上的表现,在 Coop(室内近距离摄像头,人物无表情)测试集上的重建精度达到了 SOTA 水平。
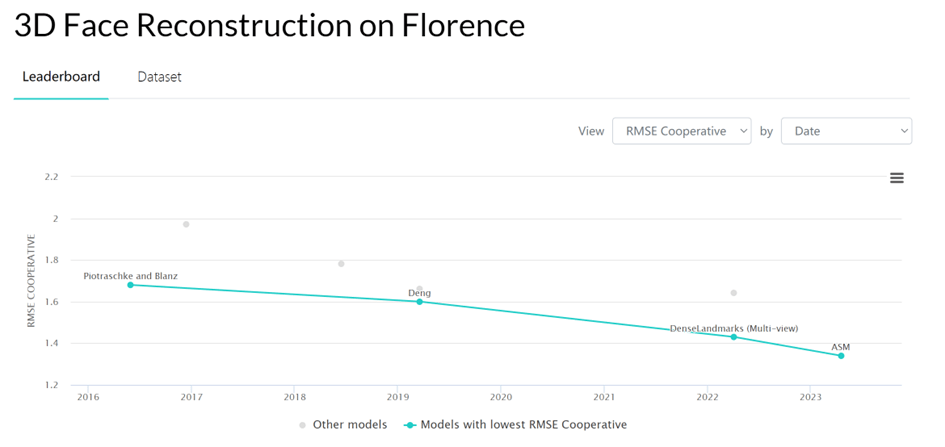
我们还在 FaceScape 数据集上测试了多视角重建任务中图片数量对重建结果的影响,结果能够正常的看到当图片数量在 5 张左右时 ASM 相比其他的人脸表达方式可以在一定程度上完成最高的重建精度。
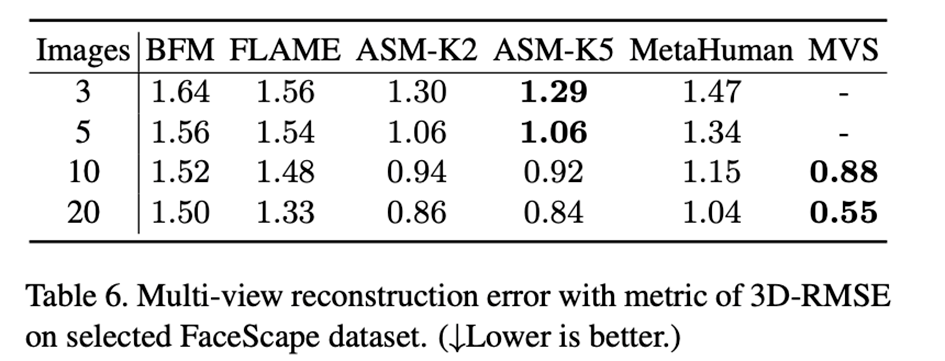
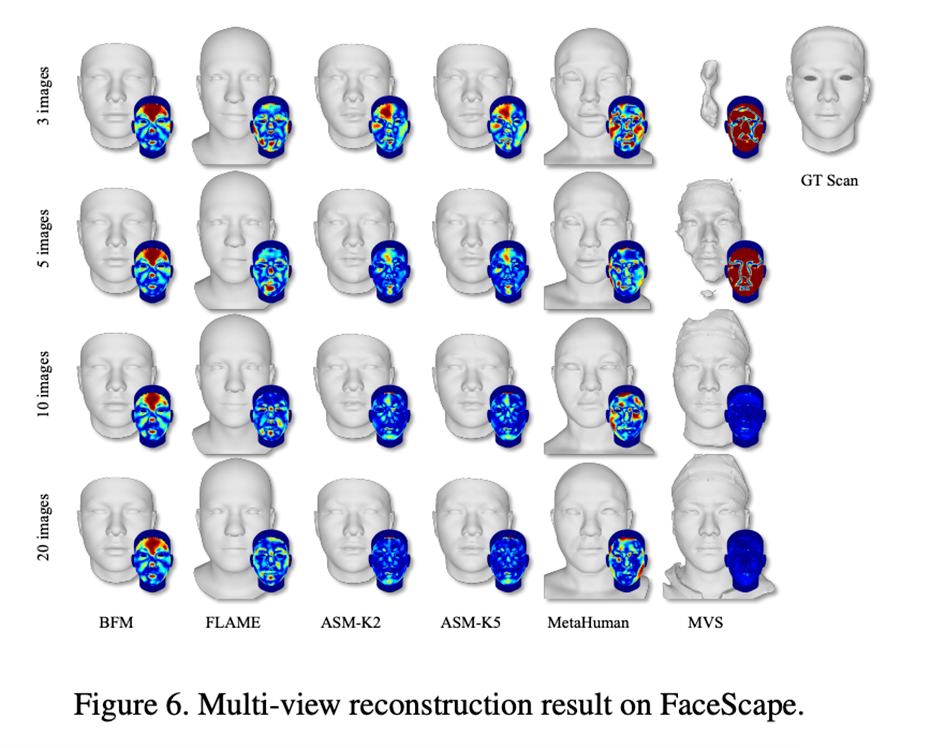
图 5:FaceScape 上不同输入数量的多视角重建可视化结果与误差热力图
在低成本条件下获得高保真人脸这一行业难题上,本研究迈出了重要一步。我们提出的新参数化人脸模型明显地增强了人脸表达能力,将多视角人脸重建的精度上限提升到了新的高度。该方法可用于游戏制作中的 3D 角色建模、自动捏脸玩法,以及 AR/VR 中的虚拟形象生成等众多领域。
在人脸表达能力得到非常明显提升之后,如何从多视角图片中构建更强的一致性约束,以进一步提升重建结果的精度,成为了当前人脸重建领域的新瓶颈、新挑战。这也将是我们未来的研究方向。
- 电话:15028752820
- 邮箱:info@zhugang.com
- 地址:河北省泊头市千里屯工业区199号

冀公网安备 冀ICP备17001371号-5
Copyright © 2002-2020 bob官方平台app_bob线上官网 版权所有 XML地图
